R-tree를 사용한 가까운 마커 찾기 기능 구현과 개선기
R-tree를 사용하여 가까운 마커 찾기 기능을 구현하고, 이를 어떻게 개선했는지를 소개합니다

안녕하세요! 더스윙에서 프론트엔드 개발을 담당하고 있는 정주형이라고 합니다.
모빌리티 서비스 기업인 더스윙에서는 지도 관련 도메인을 다룰 일이 많습니다. 이번 포스팅에서는 지도와 관련된 요구사항을 구현한 내용과 그 과정에서 마주한 문제, 그리고 어떻게 개선할 수 있었는지에 대해 소개해 드리고자 합니다.
마커를 움직일때마다 500m 이내의 가장 가까운 마커가 커지게 해주세요!
다음과 같은 요구사항이 들어왔습니다. 지도에 많은 마커들(택시, 정류장 등등)이 존재하는 상황에서 사용자가 마커를 움직일때 최근접한 마커를 찾아 크기를 키워야 합니다.
복잡해 보이는 작업이니 먼저 요구사항을 작은 단위로 하나씩 분해해보도록 하겠습니다. 해당 요구사항들은 다음과 같은 작은 기능 몇가지를 필요로 합니다.
- 마커를 움직일 수 있어야 함.
- 500m 내의 마커들을 찾을 수 있어야 함.
- 움직이는 마커와 가장 가까운 마커들을 찾을 수 있어야 함
- 가장 가까운 마커의 ui를 업데이트 할 수 있어야 함.
좀 더 개발 친화적으로 정의한다면 마커를 움직이는 이벤트마다 콜백 함수를 호출, 해당 함수 내에서 현재 마커와 다른 마커들간의 거리를 비교하고, 조건에 맞다면 마커를 다시 렌더링 시켜줘야 합니다.
구현하기
뭘 구현해야 할지 정리했으니, 이제 실제로 구현을 해볼 차례입니다. 첫번째 작업인 마커를 움직일때마다 이벤트를 받을 수 있도록 해 봅시다. 구현의 경우 react와 카카오맵 sdk를 기반으로 하였습니다.
마커를 움직이려면 맵에서 특정 element를 drag 할때마다 이벤트를 쏘고, 해당 이벤트를 감지해서 우리가 만들 콜백 함수를 호출해야 합니다. 일견 복잡해보이지만 다행히 대부분의 map sdk들은 마커 드래그 이벤트와 리스너를 지원합니다.
// 도착 마커에 dragstart 이벤트를 등록합니다
kakao.maps.event.addListener(arriveMarker, 'dragstart', function() {
// 도착 마커의 드래그가 시작될 때 마커 이미지를 변경합니다
arriveMarker.setImage(arriveDragImage);
});
다음으로 움직이는 마커의 500m 이내 마커를 찾아봅시다. 아쉽게도 특정 마커의 반경 안의 마커를 찾아주는 메소드는 없으니, 직접 구현해야 합니다.
드래그 하고 있는 마커와 다른 마커들간의 직선거리를 구해서 500m 내인지 판별하면 가장 가까운 마커를 찾을 수 있을 것입니다.
마커간의 거리를 구하는 방법은 몇가지가 있습니다. 가장 간단한 방법은 두 좌표 사이에 polyline을 그리는 것입니다. 보이지 않는 가상의 선을 그어서 해당 선의 길이가 바로 마커간의 거리가 되겠죠.
const calculateDistance = (
pos1: kakao.maps.LatLng,
pos2: kakao.maps.LatLng,
): number => {
const polyline = new kakao.maps.Polyline({
path: [pos1, pos2],
})
return polyline.getLength()
...
const distance = calculateDistance(currentPosition, candidateLatLng)
// 500m 체크
if (distance > MAX_DISTANCE_METERS) {
updateNearbyMarker(null)
return
}
이렇게 빠르고 간단하게 구할 수 있습니다. 그러나 해당 접근 방식은 문제가 있습니다. 폴리라인으로 지도상에서 확인할 수 있는 두 좌표 사이의 거리가 실제로 500m가 아니라는 점입니다. 곡률을 고려하지 않았기 때문입니다.
지구는 구형이지만 맵은 평면이므로 두 점 사이의 거리는 곡률을 고려하지 않는다면 오차가 발생하게 됩니다. (다만 sdk마다 내부 구현 방식이 상이해, 이미 polyline의 길이가곡률이 고려되는 경우도 있습니다)
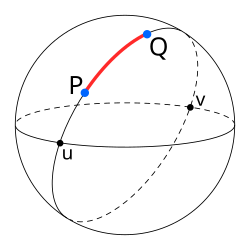
따라서 이를 보정하기 위해 구체 표면에서 거리를 계산하는 하버사인 공식을 사용할 수 있습니다. 직접 구현할 필요 없이 JS로 만들어놓은 함수를 사용해도 되고, turf js처럼 지리공간 데이터를 다루는 라이브러리를 사용할 수도 있습니다. 해당 포스팅에서는 쉬운 설명을 위해서 polyline 비교를 사용하도록 하겠습니다.
이제 구현해봅시다. 마커의 onDrag 이벤트마다 각 마커들의 위치를 계산해서, 500m 이내중 가장 가까운 마커면 updateNearbyMarker 함수를 호출합니다. updateNearbyMarker는 해당 마커의 크기를 조금 키웁니다.
// 마커의 OnDrag 콜백함수
const handleDragMove = useCallback(
(event: kakao.maps.event.MouseEvent) => {
if (!markers.length) {
return
}
const currentPosition = event.latLng
let closestId: string | null = null
let closestDistance = Infinity
markers.forEach((marker) => {
const markerPosition = new kakao.maps.LatLng(
marker.position.lat,
marker.position.lng,
)
const distance = calculateDistance(currentPosition, markerPosition)
if (distance < closestDistance) {
closestDistance = distance
closestId = marker.id
}
})
if (closestDistance > MAX_DISTANCE_METERS) {
updateNearbyMarker(null)
return
}
updateNearbyMarker(closestId)
},
[MAX_DISTANCE_METERS, calculateDistance, markers, updateNearbyMarker],
)
짜잔! 이렇게 해서 요구사항에 부합하는 기능을 완성할 수 있었습니다.
그러나.. 이미 눈치 채셨겠지만 해당 구현 방식은 문제가 있습니다. 마커가 적을때는 괜찮겠지만 마커가 100개 혹은 1000개가 된다고 생각해 보세요.
카카오맵 마커의 onDrag 이벤트는 주사율에 맞춰 프레임 단위로 호출됩니다. 1000개의 마커 있다고 했을때 대략 60ms마다 1000번의 연산을 하게 되니, 사용자가 4초 드래그를 한다고 했을때 약 66,000 ~ 67,000번의 연산을 하게 되는 셈입니다.
성급한 최적화는 악의 근원이다-라는 말이 있지만 지금은 분명 개선이 필요한 상황이라고 할 수 있을 것입니다.
최적화하기 - 공간 인덱싱
현재 구현 방식의 문제는 간단합니다. 거리 이내 마커 후보군들을 찾기 위해 모든 마커와의 거리를 계산한다는 것이 문제입니다. 효율적으로 주어진 거리 안의 마커만 찾을 수 있다면 쉽게 해결할 수 있을 것입니다.
이걸 위해서 공간 인덱싱을 사용할 수 있습니다. 공간 인덱스는 지리적 객체의 위치 정보를 효율적으로 관리하고 검색하기 위한 데이터 구조로써 이를 통해서 보다 효율적으로 특정 공간 내의 요소들을 찾게 해줍니다.
우리가 가진 문제에 해당 방법을 사용한다면 마커의 개수마다 O(n)으로 연산이 늘던 것이 O(logn)으로 줄게 되는 것입니다. 지수적으로 생각한다면 1000개 기준 125배 줄어드는 셈입니다. 놀랍죠.
문제를 해결해 봅시다. 500m보다 멀리 떨어진 마커들은 거리 계산 자체를 하지 않고, 500m 이내라면 가장 가까운 마커를 찾으면 됩니다. 이렇게 하면 후보군이 훨씬 줄어들 것입니다.
공간 인덱싱은 다음과 같은 방법들을 사용해서 각 마커들의 지리적 정보를 토대로 찾기 쉽게 그룹화합니다.
- R-tree / R-tree*: 사각형(AABB)로 묶어서 단계적으로 그룹화
- k-d tree: 축을 기준으로 공간을 나눠서 포인트 최근접(kNN)에 강한 구조
- Quadtree: 2D를 4등분씩 쪼개는 간단하고 직관적인 트리
그리드/해시 기반의 방법도 있습니다.
- Uniform grid / Geohash / H3: 격자(또는 셀)로 나눠 버킷처럼 빠르게 후보를 모음
- Z-order/Hilbert(공간 채움 곡선) + 정렬/인덱스: 2D를 1D로 펴서 빠른 범위 스캔
일반적으로는 트리 기반의 방법을 사용하니 해당 포스팅에서는 Rtree를 사용하도록 하겠습니다.
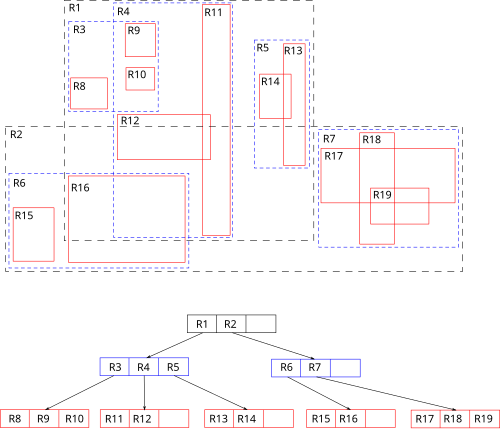
원리는 간단합니다. 현재 마커의 좌표를 기준으로 거리 내의 '겹치는 박스'들을 트리형태로 훑으면 됩니다. 트리 형태의 자료구조이므로 O(n)에서 워스트 케이스가 아닌 경우 O(log n + m(박스 내 후보군))까지의 성능 향상을 기대할 수 있습니다.
물론 균일하지 않게 마커가 몰려있는 워스트 케이스에서는 모든 박스를 다 돌아야 하므로 효과가 크지 않을 수 있습니다만, 해당 상황에서는 트리를 균일하게 만들거나 다른 구조를 사용하면 됩니다.
실제 코드로 구현해보도록 하겠습니다. 해당 포스팅에서는 js와 Rtree를 기반으로 한 구현체인 Rbush를 사용하였습니다.
const tree = getRbushInstance()
// 좌표 기준으로 500m 이내로 만든 사각형의 크기
const candidates = tree.search(boxFromMarkerPostion);
// 후보군들중에서 가까운 마커를 검색
candidates.forEach((node) => {
const candidateLatLng = new kakao.maps.LatLng(
node.data.position.lat,
node.data.position.lng,
)
const distance = calculateDistance(currentPosition, candidateLatLng)
if (distance < closestDistance) {
closestDistance = distance
closest = node
}
})
...
원리는 굉장히 간단합니다.
- 먼저 모든 마커들을 해당 tree 내에 넣습니다.
- 해당 좌표로 500m 크기의 박스(boxFromMarkerPostion)를 만듭니다.
- tree 형태로 박스에 겹치는 박스들을 조회합니다.
- 겹치지 않는다면 (거리보다 멀다면) 바로 스킵합니다.
결과값으로 나온 후보군들은 가장 가깝게 겹치는 박스의 마커들이고, 이제 해당 후보군들을 상대로 거리 계산을 해서 가장 가까운 마커를 찾으면 됩니다.
더 최적화하기 - 최근접으로 찾기
아직 끝이 아닙니다. 아까 워스트 케이스를 이야기 했었죠. 만약 박스 하나에 마커가 500개가 있다면 어떻게 될까요? 박스 자체는 빨리 찾을 수 있겠지만, 결과값으로 주어진 후보군이 500개니 다시 500번의 연산을 해야 합니다. 최적화한 보람이 없을 것입니다.
다시 요구조건을 생각해 봅시다. 요구조건은 결국 특정 마커에 가장 가까운 마커를 조회하는 것입니다.
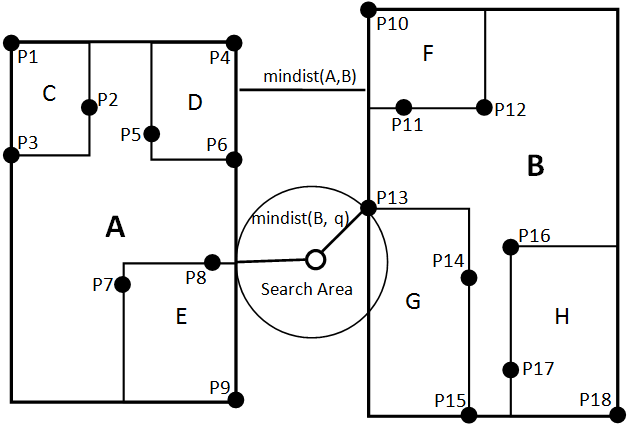
만약 해당 마커 기준 겹치는 박스로 조회하지 않고 거리가 가까운지 기준으로 트리를 훑는다면 어떨까요? 위와 같이 박스 하나에 여러개의 마커가 들어 있는 워스트 케이스들을 피할 수 있을 것입니다.
이를 위해서 rbush-knn을 사용할 수 있습니다. rbush knn은 Rbush 구현체에 knn(k-nearest neighbors최근접 이웃) 알고리즘을 사용합니다. 한줄 요약하자면 노드의 최소 가능 거리(mindist)를 기준으로 가까울 가능성이 높은 노드부터 내려가며 k개를 찾는 즉시 종료하는 알고리즘입니다.
여기에 더해서 거리 조건이나 필터링 함수를 함께 사용한다면 반경 밖/조건 불일치는 초기에 걸러 평균 탐색량을 더 줄일 수도 있습니다.
정리하면, RBush로 어디를 볼지-를 줄이고, knn으로 얼마만큼 볼지-를 최소화한 뒤, 최종 후보에만 거리를 재서 비교하면 RBush만 사용하는 것에 비해 훨씬 최적화 할 수 있습니다.
rbush knn의 구현체 코드를 보면서 설명해보겠습니다.
function knn(tree, x, y, n, predicate, maxDistance) {
let node = tree.data;
const result = [];
const toBBox = tree.toBBox;
const queue = new Queue(undefined, compareDist);
while (node) {
for (let i = 0; i < node.children.length; i++) {
const child = node.children[i];
const dist = boxDist(x, y, node.leaf ? toBBox(child) : child);
if (!maxDistance || dist <= maxDistance * maxDistance) {
queue.push({
node: child,
isItem: node.leaf,
dist
});
}
}
while (queue.length && queue.peek().isItem) {
const candidate = queue.pop().node;
if (!predicate || predicate(candidate))
result.push(candidate);
if (n && result.length === n) return result;
}
node = queue.pop();
if (node) node = node.node;
}
return result;
}
...
function boxDist(x, y, box) {
const dx = axisDist(x, box.minX, box.maxX),
dy = axisDist(y, box.minY, box.maxY);
return dx * dx + dy * dy;
}rbush tree의 루트부터 출발해서 각 노드들을 탐색합니다. 탐색하면서 우선순위 큐에 거리순으로 가까운 노드들을 넣습니다.
거리의 기준은 boxDist, 사용자가 넣은 좌표로부터 아이템 혹은 박스의 최단값입니다. 이후 루프를 돌 때마다 node를 탐색하고 아이템(leaf)에 도착하면 해당 아이템을 result에 넣습니다. 주어진 k개의 아이템이 들어온다면 중단합니다.
포인트는 최단거리를 계속해서 우선순위 큐에 넣으므로, 먼 박스들을 열 필요조차 없다는 것입니다. 아이템을 찾는 순간 해당 아이템이 주어진 좌표로부터 가장 가까운 것임이 보장되므로 빠르게 종료할 수 있습니다.
최종적으로 구현한 결과는 다음과 같습니다.
const handleOptimizedDragMove = useCallback(
(event: kakao.maps.event.MouseEvent) => {
const currentPosition = event.latLng
const tree = getRbushInstance() as RBush<RbushNode<MockMarker>>
// rbush-knn을 사용해서 후보군 좁히기
const [candidate] = knn<RbushNode<MockMarker>>(
tree,
currentPosition.getLng(),
currentPosition.getLat(),
1,
undefined,
MAX_DISTANCE_METERS,
)
if (!candidate) {
updateNearbyMarker(null)
return
}
const candidateLatLng = new kakao.maps.LatLng(
candidate.data.position.lat,
candidate.data.position.lng,
)
const distance = calculateDistance(currentPosition, candidateLatLng)
if (distance > MAX_DISTANCE_METERS) {
updateNearbyMarker(null)
return
}
updateNearbyMarker(candidate.data.id)
},
[MAX_DISTANCE_METERS, calculateDistance, updateNearbyMarker],
)얼마나 나아졌을까?
실제로 해당 방법을 적용했을때 얼마나 나아졌을까요? 사파리 개발자 도구에서 지표를 비교해 보았습니다.
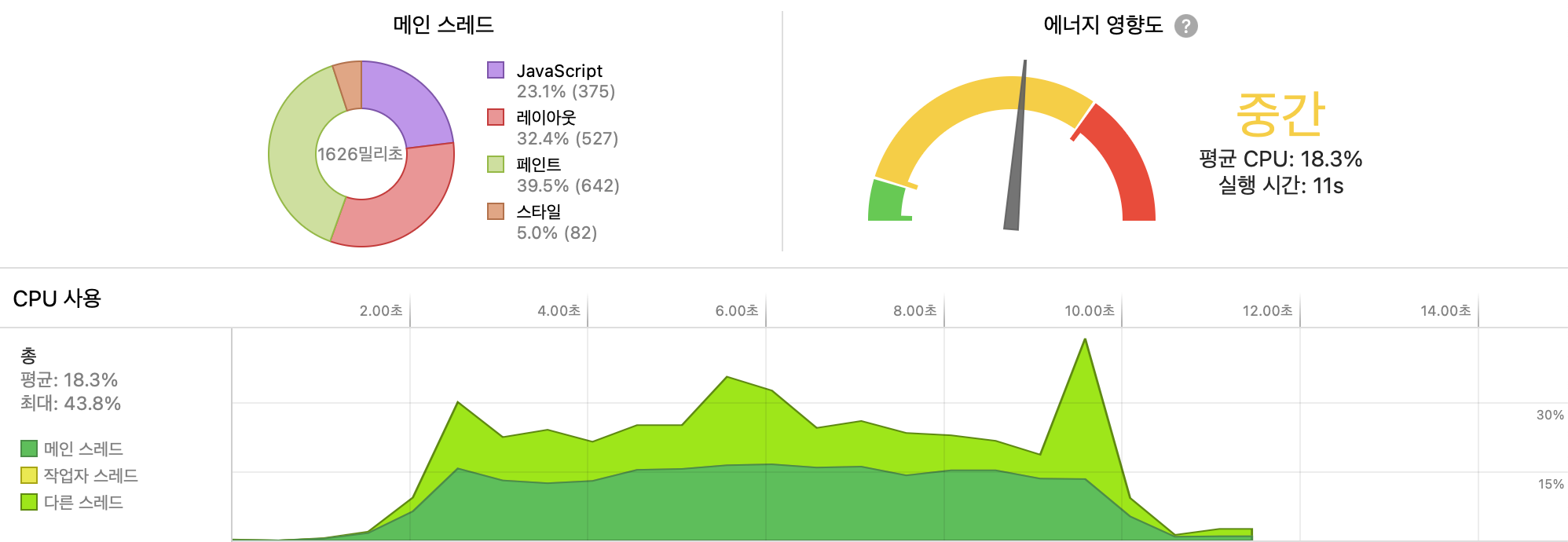
마커 100개를 기준으로 최적화를 하지 않았을때 지표입니다. cpu의 평균 사용률은 18.3, 최대 43.8%였습니다.
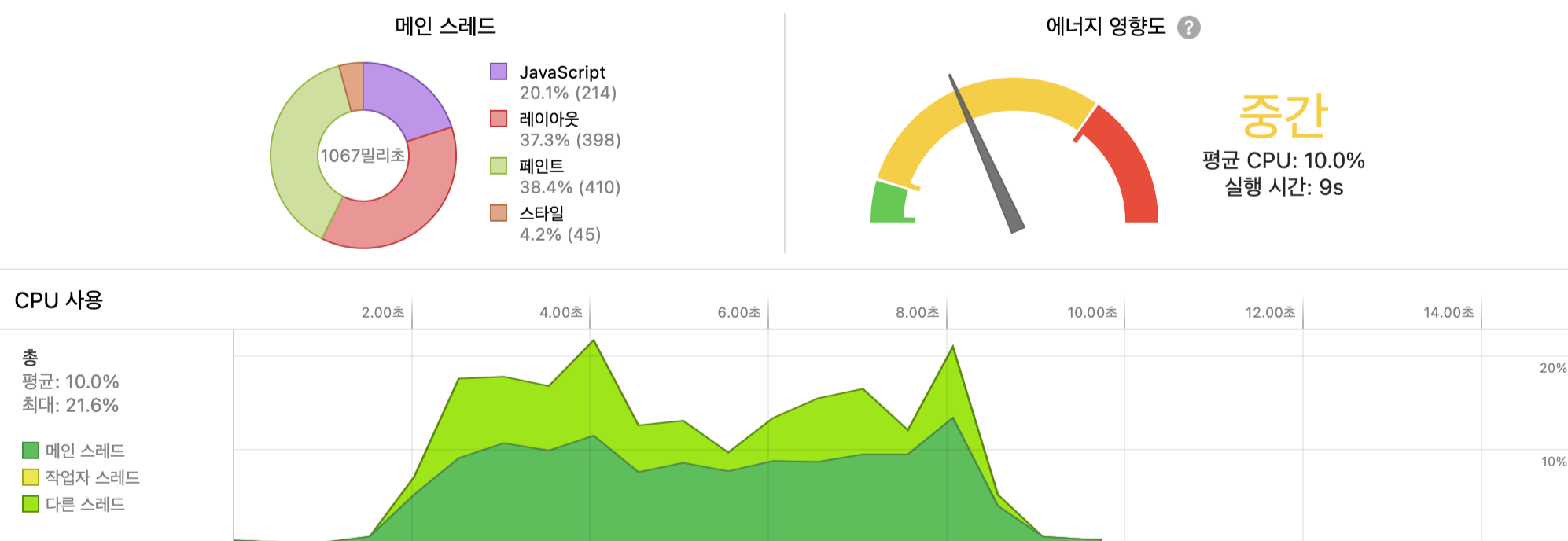
최적화를 적용하고 난 뒤의 지표입니다. 최적화를 한뒤 cpu 사용량은 평균 10%, 최대 21.6%로 줄어들었습니다.
즉 사용량이 대략 평균치는 약 45% 감소, 피크는 약 51% 감소한 것을 알 수 있었습니다.
지도를 사용하는 웹 어플리케이션은 꽤 무거우므로, 성능이 좋지 않은 데스크탑, 노트북에서는 효과를 체감할 수 있는 수준일 것입니다.
개선 후기
테스트 주도 개발 TDD의 창시자인 켄트 벡은 이렇게 말했습니다.
Make it work, make it right, make it fast
개발하는 것은 항상 무언가 사이에서 밸런스를 잡는 일이라고 생각합니다. 기간에 맞춰서 개발만 하는 것은 많은 유지보수 비용을 야기합니다. 그 반대로 성급하게 최적화 하는것도 마찬가지입니다.
개인적으로 가장 좋은 것은 켄트 벡의 말처럼 빠르게 개발한 뒤 제대로 바꾸는 것이 좋은 방안이 아닐까 합니다. 이와 같은 방법이 제품과 나아가서는 개발자 본인에게도 도움이 되는 것이 아닐까요?
해당 글이 지도나 혹은 비슷한 기능을 다루는 분들에게 조금이라도 도움이 되셨길 바라며 글을 마치도록 하겠습니다. 읽어주셔서 감사합니다.
🚖 함께 할 동료를 찾고 있어요 🚖
SWING은 더 나은 도시를 만들기 위해 노력하는 팀입니다. 데이터, 기술, 사용자 중심의 혁신을 통해 이동 경험을 바꾸고자 하는 분들을 기다리고 있습니다.
여정에 함께하고 싶다면, 지금 바로 아래 링크를 통해 지원해주세요!
👉 SWING 채용 공고 확인하기 👈