스윙 고객센터, 어떻게 응답 시간을 71% 단축했나? - 2부: Synapse AI 도입
스윙 고객센터를 어떻게 개선하여 최고의 효율성을 얻게 되었는지 총 2부로 나누어 소개합니다.
안녕하세요!
더스윙에서 개발총괄을 맡고 있는 허승균입니다.
이번 포스팅은 스윙 고객센터를 어떻게 개선하여 최고의 효율성을 얻게 되었는지
지난 1부에 이어서 2부를 소개해드리겠습니다.
Series note.
Synapse AI는 스윙의 사내 AI 플랫폼의 이름입니다.
이번 글의 주인공은 그 중 고객문의를 전담하는 Synapse Concierge이며,
이후에 시리즈로 각 제품군에 대해서 연재할 예정입니다
시작하며
1부에서 우리는 실시간 채팅 → 케이스(게시판)로 전환하며
FRT(첫 응답 시간)와 TTR(해결까지 걸리는 시간)을 함께 줄이는 구조를 만들었습니다.
그런데 게시판 전환으로 상담의 ‘허리’는 단단해졌지만,
운영을 이어가면서 이전에는 보이지 않던 새로운 문제가 드러나기 시작했습니다.
고객이 맥락을 한 번에 정리해 올릴 수 있는 바로 그 게시판 구조 때문에
케이스가 쌓일수록 새롭게 더 명확해진 병목들이 발견되었습니다.
문제: 게시판 전환 이후 드러난 세 가지 병목
① 장문 케이스의 ‘초기 해석’ 병목
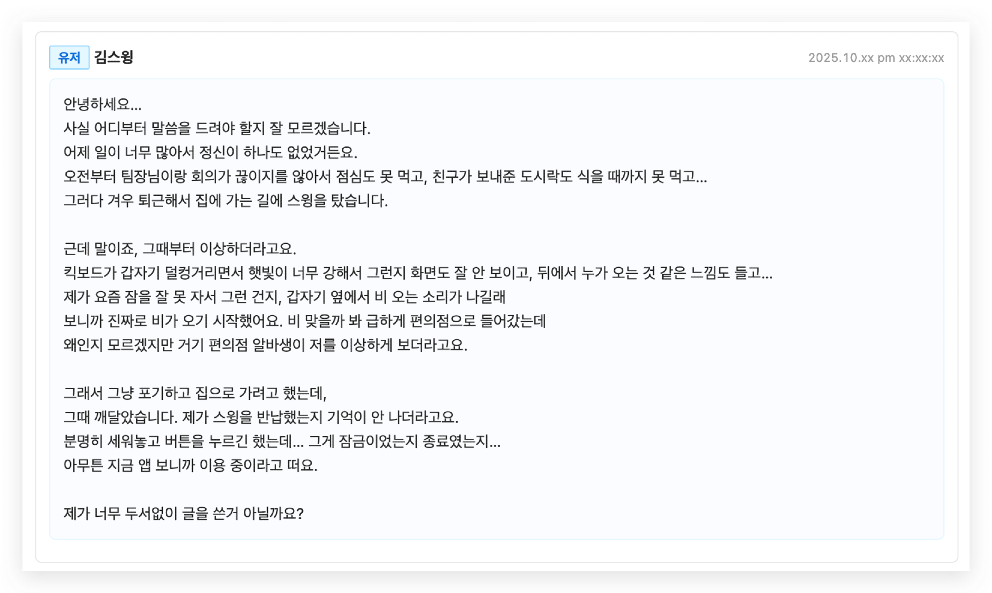
게시판은 고객이 하고 싶은 말을 한 번에 길게 적을 수 있는 환경을 제공합니다.
그만큼 맥락은 풍부해졌지만, 상담사에게는 새로운 부담이 생겼습니다.
- 핵심 이슈가 여러 문단에 흩어지고
- 고객마다 서술 방식이 달라 맥락 파악 난이도가 크게 달라지며
- 언제·어디서·어떤 기기·어떤 결제 흐름인지 다시 확인하는 데 시간이 많이 소요되었습니다.
이 과정은 상담사 개인의 독해력과 맥락 추론 능력에 크게 의존했습니다.
같은 케이스라도 상담사에 따라 해석이 달라지는 상황이 반복되었습니다.
풍부해진 맥락은 장점이었지만,
동시에 해석 비용과 편차를 높이는 요인이 되었습니다.
② 상담사별 응대 품질 편차의 ‘가시화’
케이스 기반 게시판 구조는
상담사가 작성하는 한 문장 한 문장의 차이를 그대로 드러냈습니다.
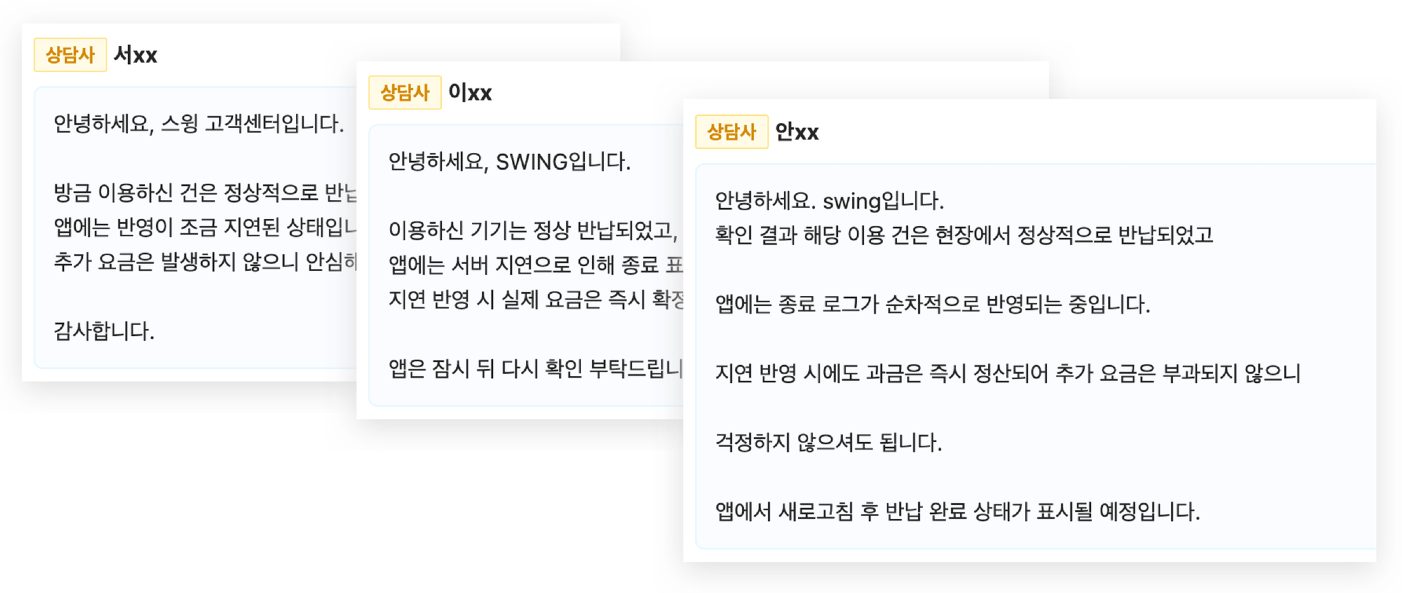
템플릿을 제공하더라도 상담사마다 다음과 같은 차이가 나타났습니다.
- 문제를 해석하는 방식
- 근거를 첨부하는 깊이와 표현
- 강조하는 정보
- 어조·형식·맞춤법 등 세세한 표현 방식
이러한 작은 차이들이 쌓여 고객이 경험하는 품질이 상담사마다 달라지는 문제가 발생했습니다.
게시판 전환은 이 편차를 오히려 더 또렷하게 보이게 했고,
지속 가능한 품질 관리를 위해 반드시 해결해야 할 핵심 과제로 자리 잡았습니다.
③ 데이터는 쌓이기 시작했지만, 이제는 연결의 문제였다
게시판 전환은 동시에 예상치 못한 기반도 만들어주었습니다.
- 케이스가 문서처럼 축적되며 유사 사례를 분류할 수 있게 되었고
- 고객 요구가 세분화되며 내부 지침서를 고도화할 여지가 생겼으며
- 정책·FAQ·유사 스레드를 연결한 지식 구조를 구축할 수 있는 환경이 갖춰졌습니다.
품질을 표준화할 준비물은 모두 마련된 셈입니다.
그러나 문제는 실행이었습니다.
정책은 계속 업데이트되고, 유사 사례는 매일 새로 생기며,
상황 조합은 끊임없이 늘어납니다.
이 모든 흐름을 사람이 기억하고, 해석하고,
매 케이스마다 일관되게 적용하는 것은 사실상 불가능했습니다.
따라서
정책 연결 → 판단 흐름 정리 → 표준 문안 적용
이 과정을 ‘사람’이 아닌 시스템 레이어가 도와주는 구조가 필요했습니다.
해결: 스레드 위에 얹은 Synapse AI 3단 레이어
앞서의 세 가지 병목은 결국 하나의 질문으로 모였습니다.
“풍부한 맥락과 쌓인 지식을, 어떻게 매 케이스에 일관되게 적용할 수 있을까?”
게시판 전환으로 기반은 갖춰졌지만,
사람이 직접 읽고, 찾고, 정리하는 방식으로는 더 이상 스케일을 감당하기 어려웠습니다.

이에 케이스 처리 흐름 위에 Synapse AI는
Databricks 기반 Data Lake에 축적된 고객 행동·운행·결제·IoT 로그·정책 문서 등의 맥락을 결합하고,
이를 LangChain 기반 Agent–LLM과 자동으로 연결함으로써
케이스마다 일관된 정보·근거·초안을 제공하는
3단 레이어 — 요약 → 검색 → 작성을 더하는 전략을 선택했습니다.
1단계 — 요약봇: 장문 케이스를 ‘읽을 수 있는 단위’로
요약봇은 케이스가 열리는 순간,
긴 고객 메시지를 구조화된 카드 하나로 자동 정리합니다.
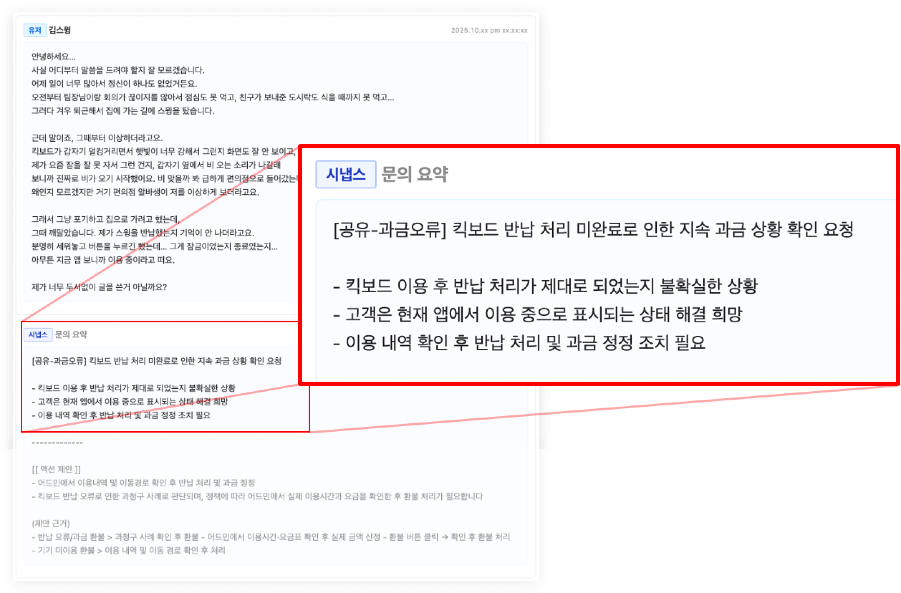
- 핵심 의도 및 주요 쟁점
- 내부 컨텍스트(로그·장비·결제 흐름)와 누락 정보
- 참고할 유사 스레드
이를 통해 상담사는 장문을 처음부터 끝까지 읽지 않고도
바로 이해와 판단을 시작할 수 있습니다.
요약봇은 상담사 간 독해 편차를 줄이고,
초기 해석 시간을 가장 크게 줄여준 기능이 되었습니다.
2단계 — 정책 RAG: 기준을 먼저 보여주는 구조
두 번째 병목은 상담사별 품질 편차였습니다.
정책을 찾고 해석하는 과정이 사람마다 달랐기 때문입니다.
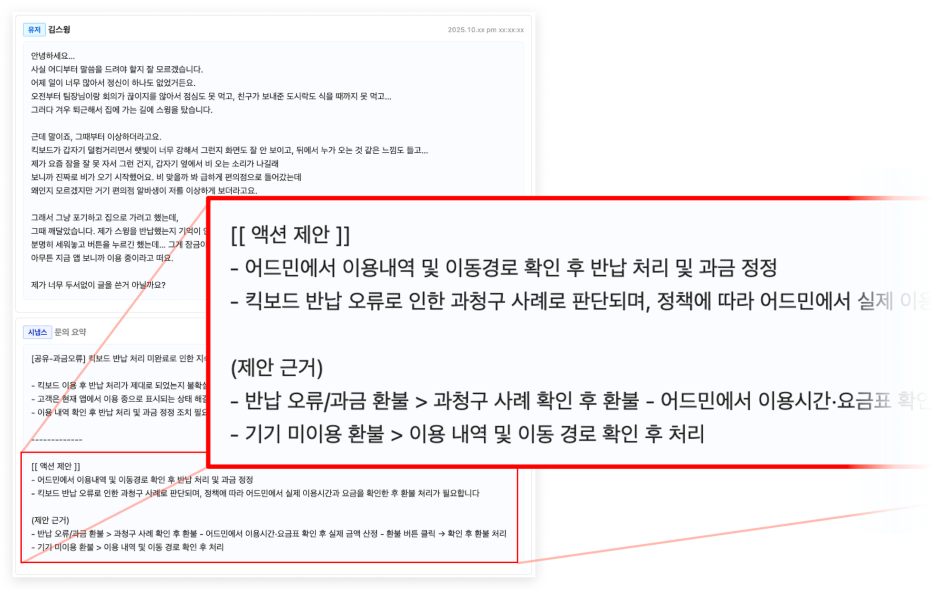
정책 RAG는 케이스의 슬롯(intent·기기·긴급도 등)을 기반으로
관련 정책·FAQ·유사 스레드를 자동으로 불러옵니다.
- 정책: 정합성 우선
- 유사 스레드: 근접도 우선
- FAQ: 패턴 우선
이 정보는 상담사가 답변을 작성하기 전에 먼저 제시되며,
모든 케이스가 동일한 기준점에서 출발할 수 있도록 합니다.
슬랙·위키·문서를 찾아다닐 필요도 없어졌습니다.
3단계 — 글짓기 봇: 판단만 사람이, 문장은 AI가
정책과 맥락이 정리되면
이제 “이 정보를 고객에게 어떻게 전달할 것인가”의 문제가 남습니다.
이 단계는 상담사가 가장 많은 시간과 에너지를 쓰던 구간이었고,
작은 표현 하나가 고객 경험을 크게 좌우하는 민감한 영역이었습니다.
그래서 사람이 해야 하는 ‘판단’(HITL) 영역과
AI가 더 정확하게 처리할 수 있는 ‘작성·정리’ 영역을 명확히 분리했습니다.
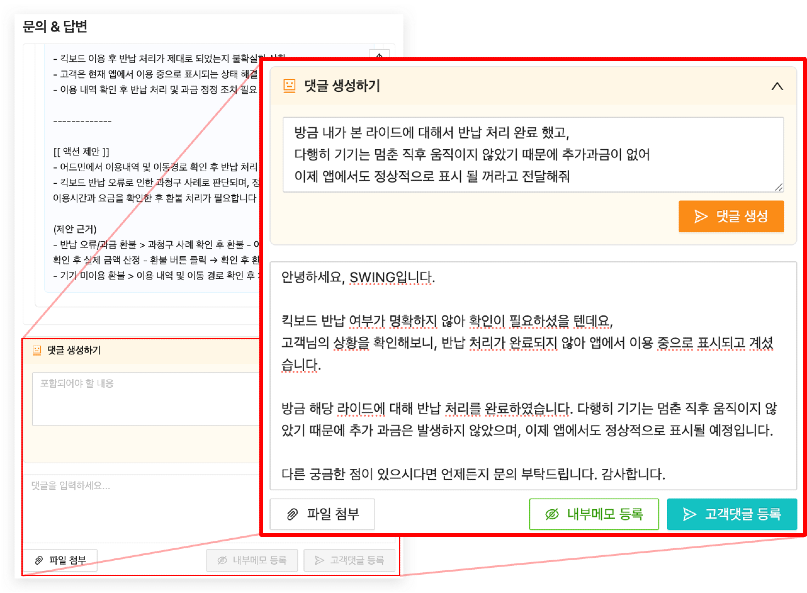
글짓기 봇은 상담사가 요구사항을 작성한 프롬프트와 함께
회사 표준 템플릿과 톤 가이드를 기반으로 다음 요소를 고려한 답변을 작성합니다:
- 현황 인식 → 공감 → 사과 → 대책 안내의 기본 응대 흐름
- 일관된 톤 & 형식
- 맞춤법·표기 자동 교정
- 상담사가 입력한 프롬프트(추가 요청·톤·주의사항 등)를 반영한 최종 문장 생성
문장의 대부분은 글짓기봇이 먼저 생성하며,
상담사는 상황 판단과 필요한 조정만 더하면 됩니다.
사람은 판단에, AI는 그 판단을 빠르고 일관되게 실행하는 구조가 완성되었습니다.
4단계 — AI Agent: End-to-End 자동 처리 (to-be)
요약 → 검색 → 작성의 흐름이 안정되면서,
일부 케이스는 사람의 개입 없이도 충분히 안전하고 일관되게 처리될 수 있는 범위가 보이기 시작했습니다.
즉, “이 정도 케이스는 사람이 보지 않아도 된다”는 기준선이 생긴 것입니다.
AI Agent는 이 기준 안에서
다음 유형의 케이스를 End-to-End로 자동 처리하도록 설계되고 있습니다.
- 단순 절차 안내
- 장비/로그 기반 사실 확인
- 반복되는 FAQ 패턴
- 명확한 정책 설명 요청
물론 자동 처리가 무조건 동작하는 방식은 아닙니다.
Summarizer–RAG–Writer 어느 단계에서라도
모호하거나 정책 충돌 가능성이 감지되면 즉시 상담사 검토(HITL)로 전환됩니다.
그 결과 상담사는 단순·반복 케이스가 아닌
고난도·경계선 케이스에 집중할 수 있는 여유를 확보하게 됩니다.
결과: 품질은 평평해지고, 속도는 더 빨라졌다
세 레이어는 각기 다른 문제를 해결했지만,
결국 하나의 흐름으로 모였습니다.
1) 상담 품질의 편차가 줄었다
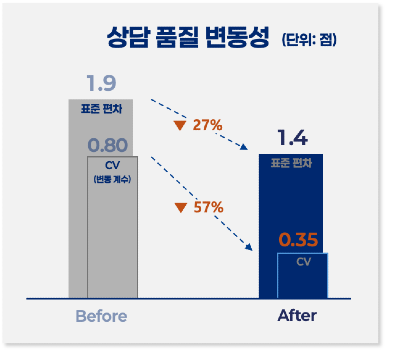
요약봇, 정책 RAG, 글짓기봇을 통해
상담사마다 달랐던 해석·작성 기준이 시스템 기준으로 정렬되었습니다.
2) 초기 해석과 기준 탐색에 소요되던 시간이 사라졌다
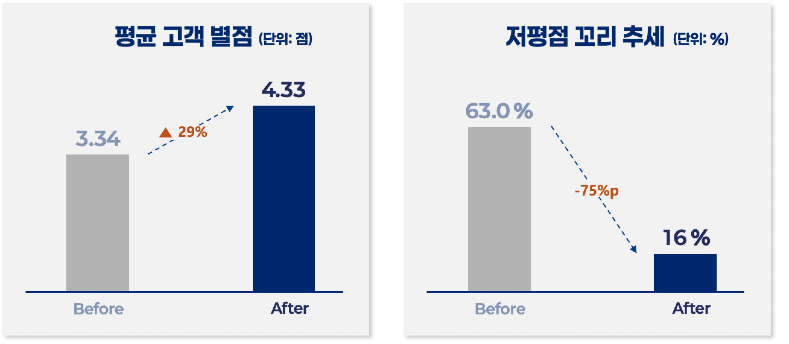
읽는 데 5분, 찾는 데 5분이 걸리던 흐름이 자동화되며
초기 해석 시간과 탐색 비용이 크게 감소했습니다.
3) 상담사는 판단에만 집중할 수 있게 되었다
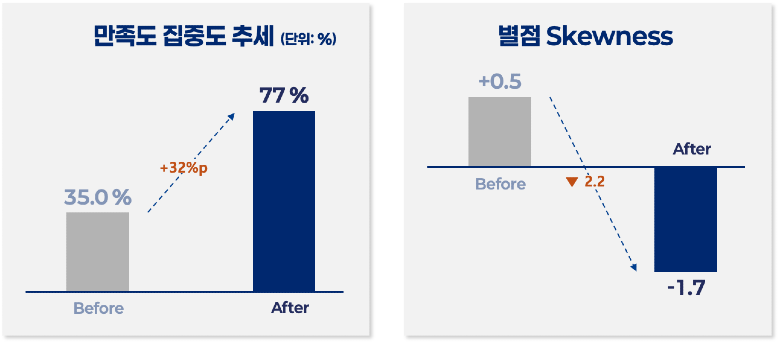
AI가 맥락 정리·근거 탐색·초안 작성까지 처리하므로,
상담사는 사람이 잘할 수 있는 판단·예외 케이스 처리·고객 경험 개선에 집중하게 되었습니다.
4) 케이스 처리량의 한계가 완전히 달라졌다
각 단계에 투입되던 인지적 비용이 줄어들며,
처리 속도뿐 아니라 처리 가능한 총량 자체가 증가했습니다.
자동화 범위 확장은 곧 전체 운영의 처리 용량 확장으로 이어졌습니다.
정리하며: 결국 문제는 ‘스케일’이었다
게시판 전환은 케이스를 명확하게 보는 데 큰 도움을 주었지만,
그 위에 쌓이는 방대한 맥락·정책·유사 사례를
매번 일관되게 적용하는 일은 사람만으로는 더 이상 감당할 수 없었습니다.
결국 우리가 마주한 진짜 문제는 스케일의 한계였습니다.
저희는
고객 메시지의 독해 → 정책·근거 탐색 → 응답 작성으로 이어지는
가장 고비용 구간을 AI 레이어로 재구성했습니다.
사람은 ‘판단’에 집중하고,
AI는 그 판단을 흐트러짐 없이, 빠르게, 매 케이스에 동일하게 실행할 수 있도록 설계했습니다.
그 결과로
- 케이스 간 응답 품질의 일관성
- 상담사 해석·작성 부담 감소
- 반복 업무 자동화
- 학습 가능한 구조적 데이터 축적
이라는 변화를 확인할 수 있었습니다.
그러나 여기서 끝은 아닙니다.
우리가 향해야 할 다음 단계는 명확합니다.
문제가 발생한 뒤 대응하는 것을 넘어,
문제가 생기기 전에 스스로 감지·판단·조치하는 Proactive Agent로 확장하는 것.
운영 시그널, 정책 변화, 내부 로그를 연결하여
사전 감지 → 자동 판단 → 자동 조치 → 사용자 안내의 흐름을 완성하는 것,
그것이 저희가 남겨둔 다음 미션입니다.
고객센터는 더 이상 ‘문의를 처리하는 곳’이 아니라,
문제를 미리 막고 운영을 스스로 최적화하는 시스템으로 진화할 것입니다.
🚖 함께 할 동료를 찾고 있습니다 🚖
SWING은 더 나은 도시를 만들기 위해 노력하는 팀입니다. 데이터, 기술, 사용자 중심의 혁신을 통해 이동 경험을 바꾸고자 하는 분들을 기다리고 있습니다.
여정에 함께하고 싶다면, 망설임 없이 지금 바로
아래 링크를 통해 지원 부탁드립니다!
👉 SWING 채용 공고 확인하기 👈